- Ana Sayfa
-
HAKKIMIZDA
-
Tarihçe
Sisoft, Ömer Siso tarafından 1987 yılında Sivas'ta Çözüm Bilgisayar adıyla kurulmuş, 1989 yılında da şirketleşerek tüzel kişilik kazanmıştır. Yazılımlarımızı o yıllarda geliştirmeye başladık. DOS tabanlı yazılımların ilki olan Çözüm Eczane ve İlaç Takip 1988 yılında, o tarihte Başhekim olan Op. Dr. Ahmet ÜSTÜN'ün talebi üzerine SSK Tokat Hastanesi için hazırlanmış, o günlerde yaygın olarak tanınan BASIC dili kullanılmıştı. Veri saklama ve kapasite sorunları yüzünden çok kısa süre içinde kodlar dBase kullanılarak yeniden yazılmıştı. Kısa bir süre sonra, tek makine ile yapılan bu işlemin ana makine kullanılarak birden fazla terminal ile yapılması istendiğinde ise, dBase'in bu işlem için pahalı olması nedeni ile Clipper Summer 87 kullanılmaya karar verilmişti. Devamı için
Vizyonumuz :
İnsan odaklı yaklaşım ile sağlık paydaşları için uçtan uca sürdürülebilir çözümler sunmak.
Misyonumuz :
Yenilikçi yazılımlar, entegre çözümler ile sağlık bilişiminin geleceğini şekillendirmek ve yaşam kalitesini artırmak.
Yönetim Kurulu :
Yönetim Kurulu Listesini Görmek İçin Tıklayınız.Üyeliklerimiz
Tanıtım Filmleri
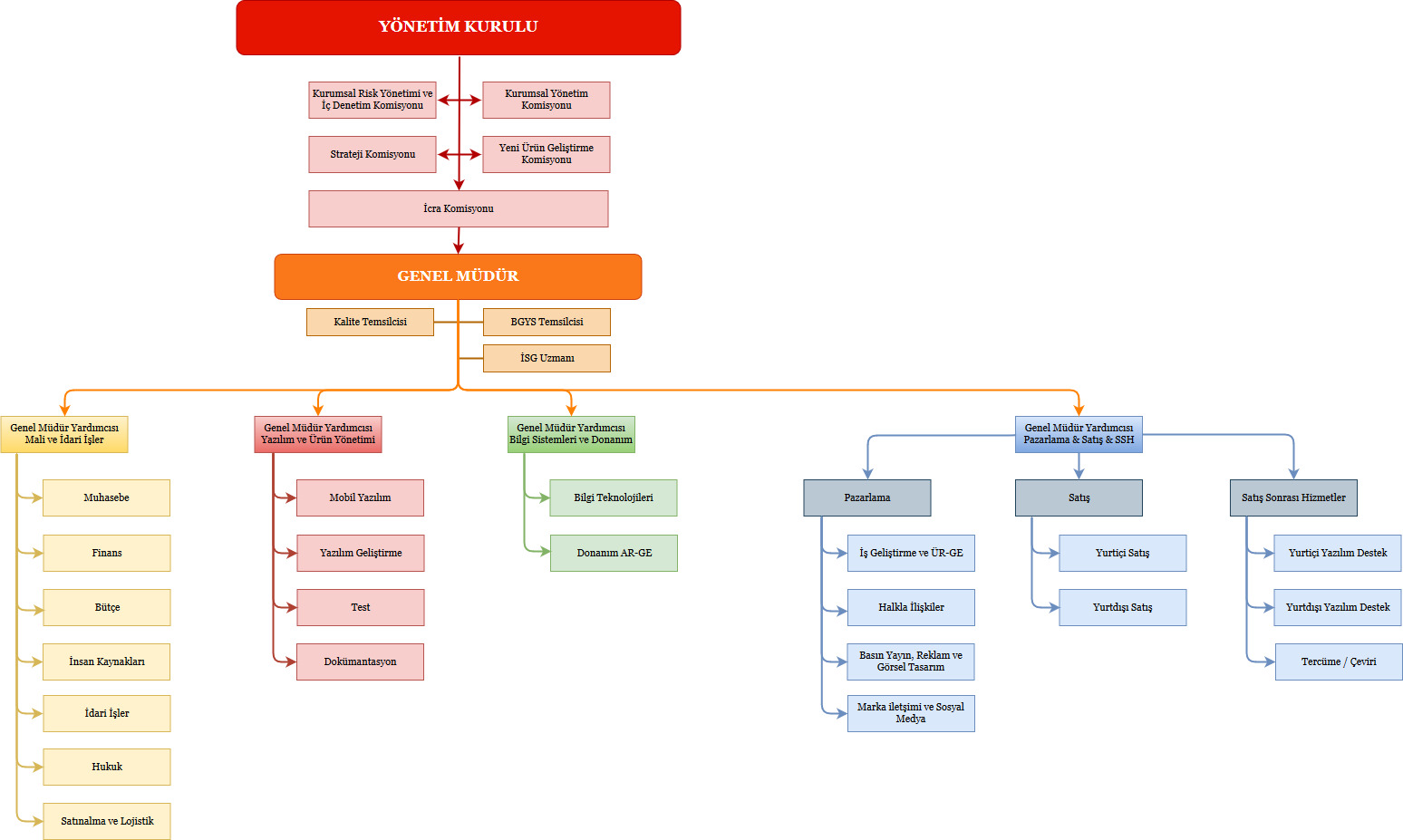
Organizasyon Şeması
-
-
ÜRÜNLERİMİZ
-
Tüm Sisoft ürünleri, ileri seviye mühendislik ve güvenlik süreçlerinden geçerek sunulmaktadır.
-
-
BAŞARILARIMIZ
-
YAYINLARIMIZ
-
İLETİŞİM











{kind=link}
ÜROLOJİ BRANŞI İLE İLGİLİ HASTALIKLARIN VERİ MADENCİLİĞİ YÖNTEMLERİ İLE TAHMİNİ
ANKARA,2019
Hastalıkların teşhis edilmesi doktorlar için önemli bir karar aşamasıdır. Çoğu zaman görüntü ve sayısal verilere dayanarak karar verildiği için hata yapma olasılığı da vardır. Özellikle görüntülerde farklı durumlardan kaynaklanan veriler yanlış teşhise yol açabilir. Günümüzde tıp dünyası, bilgisayar ve elektronik ürünlerine en çok ilgi gösteren alandır. Bu yöntemler, tıp dünyasında hastalık teşhisinde ve tedavisinde doktorların karar vermesine yardımcı olmaktadır. Bu çalışmada üroloji branşı ile ilgili hastalıkların teşhis ve tahmini çalışmaları yapılmıştır.
1. GİRİŞ
Veri madenciliği büyük veri setlerinden önemli bilgileri elde ettiğimiz bir süreçtir. Bankacılıkta risk analizlerinde, sigortacılıkta usulsüzlüklerin önlenmesinde, tıp alanında hastalığın teşhisinde, endüstri alanında kalite kontrole kadar oldukça geniş bir uygulama alanı vardır.
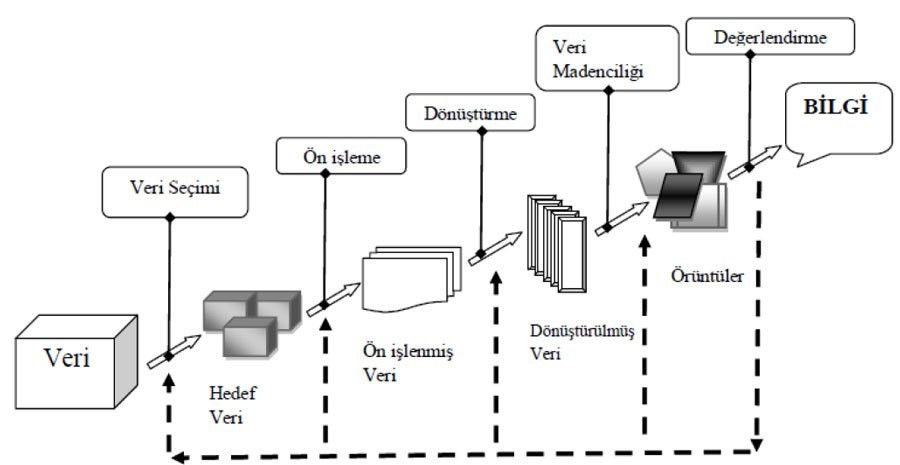
Veri madenciliği aşağıdaki süreçlerden oluşur:
1.Verilerin temizlenmesi
2.Verilerin birleştirilmesi
3.Gerekli verilerin seçilmesi
4.Verilerin uygun hale dönüştürülmesi
5.Veri madenciliği
6.Elde edilen örüntülerin analizi
2. Veri Madenciliğinde Karşılaşılan Problemler
Büyük hacimli verilerin bulunduğu veri ortamlarında büyük sorunlar ortaya çıkabilir. Bu nedenle küçük veri kümelerinde, benzetim ortamlarında hazırlanmış veri madenciliği sistemleri, büyük hacimli, eksik, gürültülü, boş, atık, aykırı veya belirsiz veri kümelerinin bulunduğu ortamlarda yanlış çalışabilir. Bu nedenle veri madenciliği sistemleri hazırlanırken bu sorunların çözülmesi gerekmektedir.
Veri madenciliği uygulamalarında karşılaşılabilecek sorunlar şunlardır:
Artık veri:
Artık veri, problemde istenilen sonucu elde etmek için kullanılan örneklem kümesindeki gereksiz niteliklerdir. Bu durum pek çok işlem sırasında karşımıza çıkabilir.
Veri tabanları genel olarak basit öğrenme işlerini sağlayan özellik veya nitelikleri sunmak gibi veri madenciliği dışındaki amaçlar için hazırlanmışlardır. Bu yüzden, öğrenme görevini kolaylaştıracak bazı özellikler bulunmayabilir.Boş veri:
Bir veri tabanında boş değer, birincil anahtarda yer almayan herhangi bir niteliğin değeri olabilir. Boş değer, tanımı gereği kendisi de dâhil olmak üzere hiçbir değere eşit olmayan değerdir.
Eksik veri:
Veri kümesinin büyüklüğünden ya da doğasından kaynaklanmaktadır. Eksik veriler olduğunda yapılması gerekenler şunlardır:
• Eksik veri içeren kayıt veya kayıtlar çıkarılabilir.
• Değişkenin ortalaması eksik verilerin yerine kullanılabilir.
• Var olan verilere dayalı olarak en uygun değer kullanılabilir.
Eksik veriler, yapılacak olan istatistiksel analizlerde önemli problemler yaratmaktadır. Çünkü istatistiksel analizler ve bu analizlerin yapılmasına olanak veren ilgili paket programlar, verilerin tümünün var olduğu durumlar için geliştirilmiştir.
Farklı tipteki verileri ele alma:
Gerçek hayattaki uygulamalar makine öğreniminde olduğu gibi yalnızca sembolik veya kategorik veri türleri değil, fakat aynı zamanda tamsayı, kesirli sayılar, çoklu ortam verisi, coğrafi bilgi içeren veri gibi farklı tipteki veriler üzerinde işlem yapılmasını gerektirir.
Gürültülü ve kayıp değerler:
Veri girişi veya veri toplanması esnasında oluşan sistem dışı hatalara gürültü denir. Büyük veri tabanlarında pek çok niteliğin değeri yanlış olabilir. Veri toplanması esnasında oluşan hatalara ölçümden kaynaklanan hatalar da dâhil olmaktadır. Bu hataların sonucu olarak birçok niteliğin değeri yanlış olabilir ve bu yanlışlardan dolayı veri madenciliği amacına tam olarak ulaşmayabilir.
Sınırlı bilgi:
Veri tabanları genel olarak basit öğrenme işlerini sağlayan özellik veya nitelikleri sunmak gibi veri madenciliği dışındaki amaçlar için hazırlanmışlardır. Bu yüzden, öğrenme görevini kolaylaştıracak bazı özellikler bulunmayabilir.
Veri tabanı boyutu:
Veri tabanı boyutları büyük bir hızla artmaktadır. Veri tabanı algoritması çok sayıda küçük örneklemi ele alabilecek biçimde geliştirilmiştir. Aynı algoritmaların yüzlerce kat büyük örneklemlerde kullanılabilmesi için çok dikkat gerekmektedir.
Veri madenciliği analizlerine geçmeden önce ilk olarak verilerin uygun hale getirilmesi gerekmektedir.
Veri madenciliği yöntemleri; kural çıkarma, sınıflandırma ve kümeleme olmak üzere üç genel başlık altında toplanabilir. Kural çıkarma yöntemi olarak en çok kullanılan yöntem Apriori yöntemidir. Sınıflandırma yöntemleri; Karar Ağacı (KA), Bayesian Sınıflandırma (BS) ve Yapay Sinir Ağlarıdır (YSA). Kümeleme yöntemleri ise K-ortalama ve Genetik Algoritma (GA) önemli yöntemlerdir. Bu çalışmada en sık görülen 20 farklı hastalık teşhisi için sınıflandırma yöntemleri kullanılmış ve sonuçlar karşılaştırılmıştır.
İki böbrek, iki idrar borusu, idrar torbası, yani mesane ve idrar yolundan meydana gelen ve vücuda zararlı, yararsız veya fazla gelen maddeleri atmaya yarayan organlar boşaltım sistemini oluştururlar. Boşaltım sisteminin hastalıklarında ilk belirtiler ağrı, idrar etme düzensizlikleri ve vücutta ödem dediğimiz su toplanması gibi bozukluklardır. Güç idrar etmeye ve bu esnada yanma ve ağrı duymaya tıp dilinde dizüri adı verilir.
Bu çalışmada böbrek, idrar yolları ve üreme sistemi bozukluklarının teşhisi için sınıflandırma yöntemleri uygulanmış ve algoritmalar karşılaştırılmıştır.
Weka içerisinde yer alan J48 Algoritması, Random Forest Algoritması, RePTree algoritması, Decision Table, AdaboostM1 algoritması, IBk Algoritması (K en yakın komşu), Kstar algoritması, MultilayerPerceptron algoritması, regresyon algoritması (logistic) ve NaiveBayes algoritmaları model üzerinde uygulanmıştır.
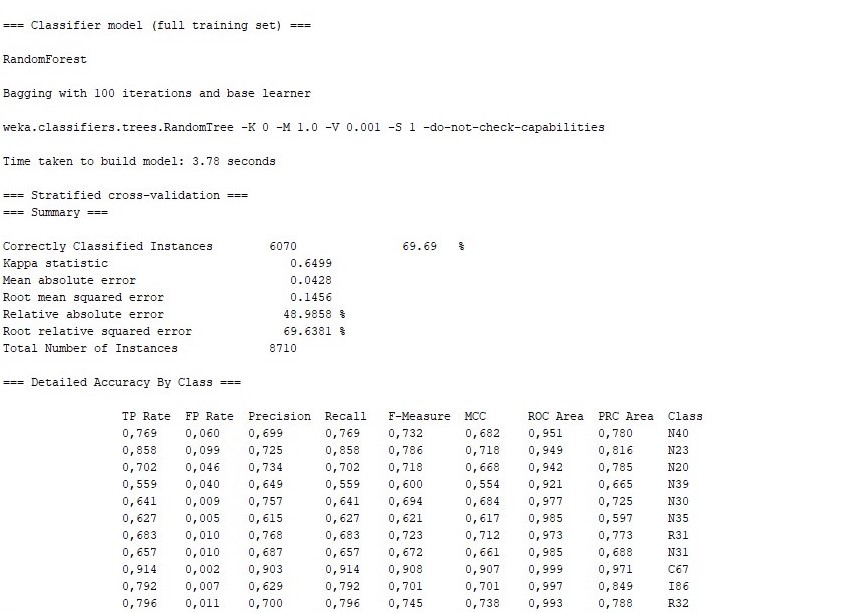
Tablo 2’den de görüldüğü gibi doğruluğu en yüksek sınıflandırma algoritması Randomforest algoritması olduğu için uygulamanın diğer bölümlerinde Randomforest algoritması esas alınacaktır.
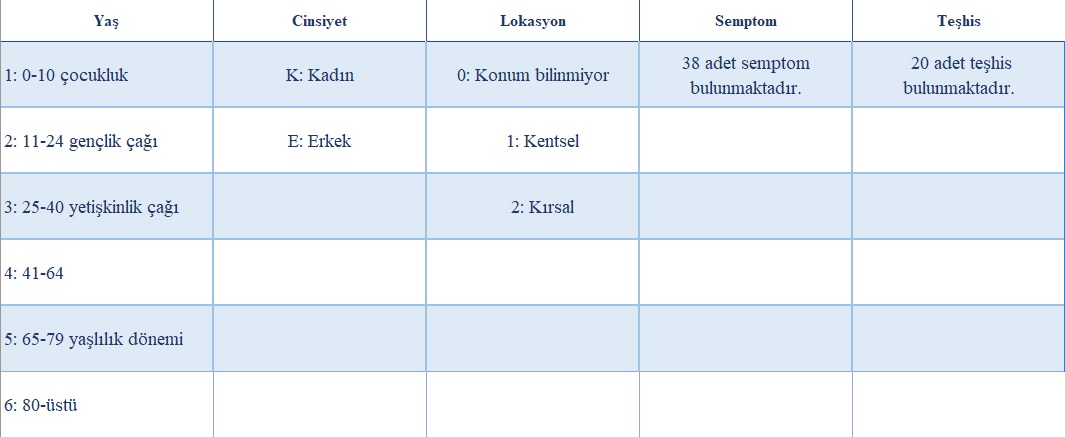
Bu veri tabanında hastalara ait 5 değişken tipi bulunmaktadır:
Verilerde hastalara ait hasta numarası, yaş, cinsiyet, lokasyon ,medeni hal, uyruk, özür durumu, semptom ve teşhis verileri bulunmaktadır. Bu verilerin bazılarında eksik gözlemler, aykırı değerler ve kayıp gözlemler bulunmakta olup model başarımına olumsuz etki yaratacağı düşünüldüğü için bu veriler tespit edilerek temizleme yapılmıştır ve tüm veriler tek bir dosyada birleştirilmiştir.Veri setinde bulunan sayısal değerler içinde gruplamalar yapılmıştır.
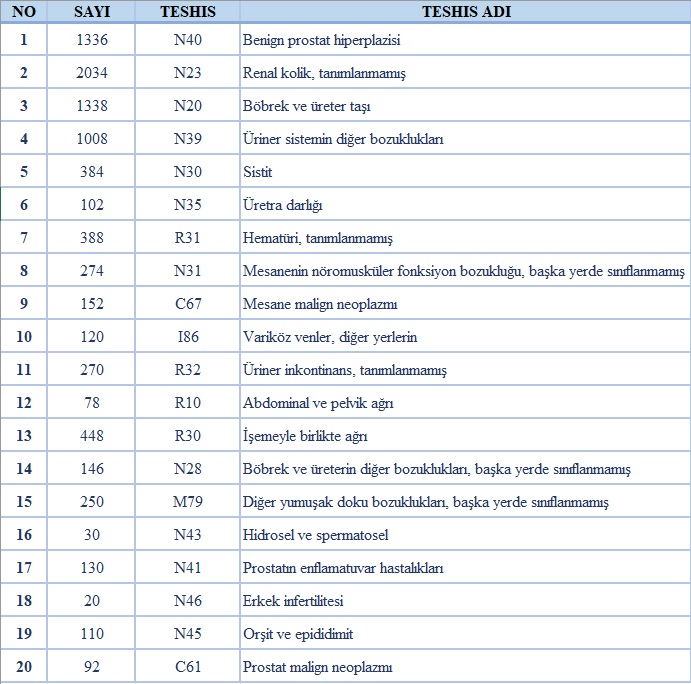
• Teşhis Listesi
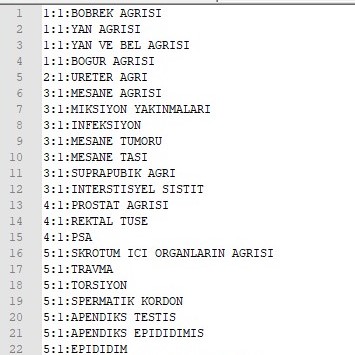
• Semptom Listesi
Semptom listesi 38 semptomdan oluşmaktadır. Bir kısmı yandaki tabloda görülmektedir:
3. UYGULAMA
3.1.Veri Madenciliği Analizleri ve Modellerin Uygulanması
Veri önişleme basamağından sonra modelleme basamağına geçilmiştir. Farklı algoritmalar veri seti üzerinde denenerek başarı oranları karşılaştırılmış ve en yüksek başarı oranını veren algoritma seçilmiştir.
3.1.2.Modeller
Sınıflandırma, yeni bir nesnenin niteliklerini inceleyerek bu nesnenin daha önceden oluşturulmuş bir sınıfa atanmasıdır. Sınıflandırma, işlerinde esas öncelik, ayrı ayrı tüm sınıfların özelliklerinin açıkça saptanmış olmasıdır.
Karar Ağaçları
Karar ağaçları, yapılandırılması ve anlaşılması diğer algoritmalara kıyasla daha kolay olduğundan, sınıflandırma problemlerinin çözümünde en çok kullanılan algoritmalardan biridir.
Karar ağaçlarına dayalı olarak geliştirilen birçok algoritma vardır. Bunlardan bazıları;
RandomForest Algoritmasına göre;
Model başarısı %69,69 olarak çıkmıştır. Teşhisleri tahmin etmede %69,69’luk bir başarı görülmektedir ve 8710 veriden 6070 tanesi doğru olarak teşhis edilmektedir.
• RandomTree Algoritmasına göre sonuçlar
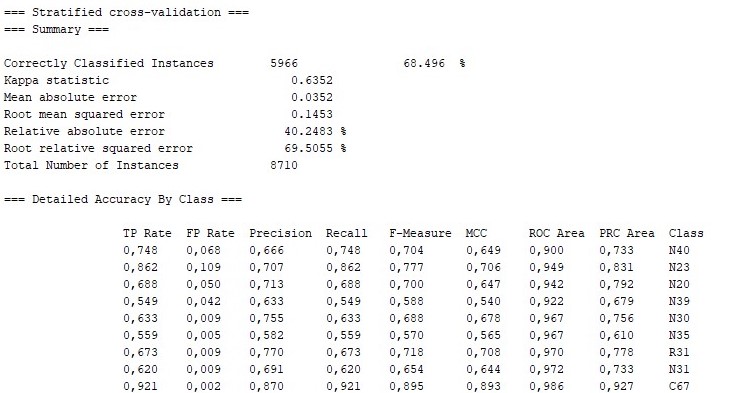
Karışıklık Matrisi
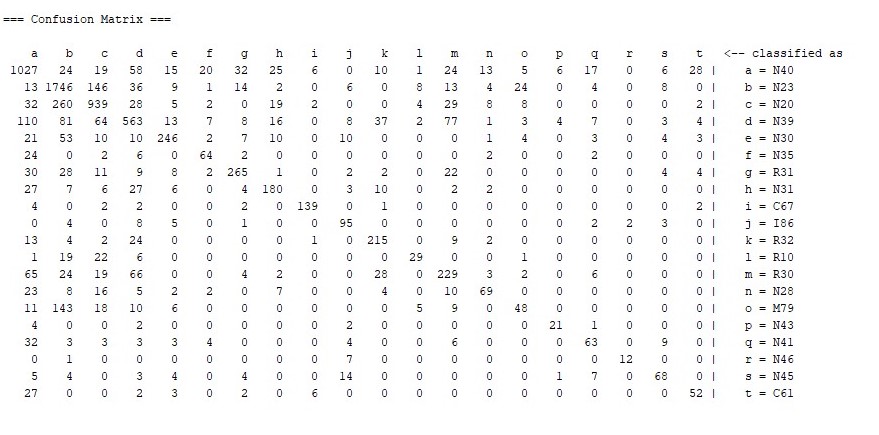
• Karışıklık Matrisi (Confusion Matris): Sınıflama problemlerinde sonuçları anlamak için çok kullanışlıdır. Gerçek değerler ile tahmin edilen değerleri aynı tabloda verir. Karışıklık Matrisi yalnızca modelin nasıl tahmin edildiğini değil, aynı zamanda yanlış sınıflananların nerede olduğunu detaylı biçimde gösterir.
• 1336 tane N40 Benign Prostat hiperplazisi verisinden 1027 tanesi doğru olarak teşhis edilmiştir.
• 2034 tane N23 Renal kolik, tanımlanmamış verisinden 1746 tanesi doğru olarak teşhis edilmiştir.

Grafikte; kadınlara ait teşhislerin dağılımı yukarıda, erkeklere ait teşhislerin dağılımı ise aşağıda görülmektedir.
Karar Ağacı
Tablo1 ’de verilen değerlere göre oluşturulan karar ağacına göre sınıflandırma yapalım.

• Yaş 3 (25-40 yetişkinlik çağı) ise, Cinsiyet Erkek ve semptom13 (Pollaküri)= 1 ise (görülmüş ise) N45 (Orşit ve epididimit) (8/2) görülme olasılığı 0,25’tir.
• Yaş= 5 (65-79 yaşlılık dönemi) ise, semptom21 = 1 (görülmüş), semptom14 = 1 (görülmüş) N20 (Böbrek ve üreter taşı) (4/2) 0,5 olasılıkla görülür.
• Yaş= 5 (65-79 yaşlılık dönemi) ise, Semptom 15 =1 (görülmüş) ise N39 (Üriner sistemin diğer bozuklukları) (8/2) 0,25 olasılıkla görülür.
Karar ağaçları, model kurulumu ve sonuçlarının yorumlanmasının kolay olması, veri tabanı sistemleri ile kolayca entegre edilebilmeleri ve güvenilirliklerinin iyi olması nedenleri ile sınıflama modelleri içerisinde en yaygın kullanıma sahip tekniklerdir.
4. MODELLERİN KARŞILAŞTIRILMASI

Yukarıda yer alan uygulama sonuçları incelendiğinde, doğruluk ölçütü açısından en iyi sonuç %69,69 değeri ile RandomForest ile elde edilmiştir. Bu algoritmayı IBk, RandomTree ve KStar algoritmaları takip etmektedir.
Kappa İstatistik Değeri, gözlenen doğruluk ile beklenen doğruluğu karşılaştıran, var olan sınıflara yapılan atamalar arasındaki uyuşmayı gösteren bir istatiksel yöntemdir. RandomForest a-Algoritması 0,6499 değeriyle en yüksek kappa istatistik değerini veren algoritma çıkmıştır. Kappa istatistik değerinin 0,6 ile 0,8 arasında olması önemli derece de uyum olduğunu, tesadüfi bir tahminde bulunmadığını göstermektedir.
F Ölçütü: 0,689 ve ROC Area değeri: 0,954 olarak çıkmıştır. Bu değişkenlerin 1’e yakın olması istenir.
5. SONUÇLAR
Doktorların daha kolay karar vermesi için üroloji branşı ile ilgili hastalıklar için veri madenciliği yöntemleri kullanılarak sınıflandırma ve kural çıkartma yapılmıştır. Üroloji branşı ile ilgili toplanan 8710 veri hastalıkların teşhis ve tahmini için kullanılmıştır. Girdi olarak verilen 8710 veriden 6070 tanesi doğru olarak sınıflanmıştır. Bu çalışmayla elde edilen bilgisayar destekli karar verme sistemi üzerinde %69,69 oranında başarılı sonuçlar alınmıştır.
Veri Madenciliği uygulamaları yapmak için bilgisayar programlarına ihtiyaç vardır. Bu programlar içerisinde veri kümeleme, karar ağaçları, bayes sınıflandırıcılar, apriori yöntemi gibi birçok algoritma bulunmaktadır. Algoritmalar sayesinde işlenen verilerden, bilgi çıkarımı yapılabilmektedir. Bu çalışmada Veri Madenciliği programlarından WEKA üzerinden analizler yapılmış ve sonuçlar incelenmiştir. Gerçekleştirilen uygulamadan elde edilen sonuçların üroloji branşı için yararlı olacağı düşünülmüştür.
6. KAYNAKLAR
1. Reed R. Pruning algorithms- A survey, IEEE TRANS. ON NEURAL NETWORKS Vol. 4 (2), pp. 740-747, 1996
2. http://w3.gazi.edu.tr/~suatozdemir/teaching/dm/slides/01.DM.Intro.pdf
3. Pang-Ning Tan, Michael Steinbach, Vipin Kumar (2005). Introduction to Data Mining. Addison Wesley, ISBN: 0-321-32136-7
4. David J. Hand, Heikki Mannila, and Padhraic Smyth (2001). Principles of Data Mining. MIT Press. ISBN 026208290X
5. Weka: A Tool for Data preprocessing, Classification, Ensemble, Clustering and Association Rule Mining, Shweta Srivastava Assistant Professor (CSE Department) ABES Engineering College, Ghaziabad, International Journal of Computer Applications (0975 – 8887) Volume 88 – No.10, February 2014 26
6. Arıcı H., ‘İstatistik yöntemler ve uygulamalar’, Ankara, 1993.
7. https://www.academia.edu/30879162/VERİ_MADENCİLİĞİ_VE_TÜRKİYE_DEKİ_UYGULAMA_ÖRNEKLERİ
8. http://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic)
9. https://www.academia.edu/1941251/Veri_Madencili%C4%9Fi_Y%C3%B6ntemleri_Kullan%C4%B1larak_Meme_Kanseri_H%C3%BCcrelerinin_Tahmin_ve_Te%C5%9Fhisi
10. https://docplayer.biz.tr/15128771-Veri-madenciligi-siniflandirma-ve-kumeleme-teknikleri-yardimiyla-wisconsin-veriseti-uzerinde-gogus-kanseri-teshisi-hazirlayan-nury-amanmadov.html
Sisoft Sağlık Bilgi Sistemleri, "Sağlık Bilişimi"nde ileri teknolojiye sahip alt yapısı ve uzman personeli ile yüzünü dünyaya dönmeyi başarmış, çeyrek yüzyılı aşkın bilgi ve birikime sahiptir.
Sisoft,Hastane Bilgi Sistemleri
veHastane Bilgi Yönetim Sistemleri
konularında Türkiye'nin lider kuruluşudur.Son Haberler
Hızlı Bağlantılar
İletişim
06810 Çankaya / TR
Tel: +90 850 955 74 76
Fax: +90 312 210 19 24
Email: sisoft@sisoft.com.tr
2025 © Tüm hakları saklıdır. Gizlilik Sözleşmesi | Kullanım Hakları |Kişisel Verilerin Korunması | Çerez Politikası | Kalite Politikası | BGYS Politikası | İSG Politikası
Bu web sitesi sadece işlem güvenliği amaçlı çerez kullanmaktadır. Bu web sitesini kullanarak bu çerezleri kullanmamıza izin vermiş oluyorsunuz. Daha Fazlası için Çerez Politikamızı Okuyun.